
How I Write Elm Applications
Most of my work over the past 10 years has involved writing what is often called a wizard.
A wizard is essentially a multi-step process that guides a user through a particular workflow. For example, if you are installing a new application on your computer, the wizard might guide you through the following process:
- Enter your license registration details
- Agree to the software author’s legal terms
- Specify an installation location
Most web applications provide something similar. If a user needs to input a large amount of data for the application to then run a bunch of calculations, you could of course just provide the user with one big web form. At a certain size though, a single web form can be intimidating and provide a less than ideal user experience. The canonical way to improve the user experience here is to break up the web form into several separate pages. This is another example of a wizard.
I’ve tried writing wizards in a number of different web technologies, and so far Elm has proven itself as by far the most robust and painless, especially when it inevitably comes to changing some conditional logic to meet the mutable needs of various business processes.
For any small Elm application, project structure is easy. There is no reason why a 1,000 line Elm application can’t live in a single file. In fact this is really how every Elm application ought to begin its life. Start with a single file with the usual boilerplate and the following contents:
- A single sum type to model all of the messages your application supports
- A single model which contains all the application state
- A single update function for advancing the application state
- A single view function for rendering the application state on the page
If your web form is complex enough to warrant being broken into separate pages
however, then your application is naturally not going to consist of a small
number of lines of code. A common concern among less experienced Elm
programmers is that one big sum type for all of your messages becomes unwieldy
to maintain. The same is said of having one big shallow record for all of the
application state, or one big update function to match all the constructors
of the one big Msg type. This is where unnecessary complexity starts to
balloon as programmers add clever abstractions and misdirections, usually
involving both Html.map and Cmd.map, separate update functions for each
logical subsection of your application (usually with noticeably awkward type
signatures), and some vague hand-waving in the direction of encapsulation and
so-called Clean Code.
I’d argue that this kind of misdirection is almost never what you want. I’d argue further that this applies especially to you if your background is in maintaining complex React/Angular applications, where invented complexity is the status quo and this kind of misdirection is simply what you have become desensitised to.
So if the combination of Html.map and Cmd.map are to be avoided, how can we
scale an Elm application without sacrificing developer ergonomics? In short,
the tricks to employ are:
- Nested sum types
- Nested record types
- Nested update functions
- Small, composable view functions
- Function composition
- Lenses
Let’s take a look at a more concrete application of these ideas. As an example, we can model the process of a person applying for a bank loan.
The bank will want to ask the applicant a whole bunch of questions, which we could group into three categories:
- Personal information
- Details on the purpose of the loan
- Financial information and creditworthiness
This would suggest a three-step wizard or a three-page web form. A reasonable
place to begin splitting our application apart into three smaller pieces is in
our Msg type.
The Big Msg Type
The naïve way to model the messages our application should support is with one big sum type, which might look something like this:
type Page
= PersonalInformationPage
| LoanPurposePage
| FinancialDetailsPage
type Msg
-- System-wide messages
= NoOp
| SetPage Page
-- etc…
-- Personal information
| SetFirstName String
| SetLastName String
| SetAddressLine1 String
-- …more messages for the personal information page
-- Purpose of the loan
| SetPurchaseItemCategory
| SetPurchaseItemEstimatedValue
-- …more messages for the loan purpose page
-- Financial information
| SetMonthlyIncomeBeforeTax
| SetMonthlyRentPayment
-- …more messages about the applicant's financial details
This does work, but at some point it becomes cumbersome to support a large
number of constructors. The value for “large” is of course determined by the
individual programmer’s personal taste and/or pain threshold. To ease this
pain, people typically extract groups of messages into their own separate sum
types, which subsequently forces them to write update functions that return a
type other than the top-level Msg type.
Don’t do that!
The way to break these groups of constructors out is by first nesting them
inside the Msg type, like this:
type PersonalInformationMsg
= SetFirstName String
| SetLastName String
| SetAddressLine1 String
-- etc..
type LoanPurposeMsg -- etc…
type FinancialDetailsMsg -- etc…
type Msg
= NoOp
| SetPage Page
| PersonalInformationMsg PersonalInformationMsg
| LoanPurposeMsg LoanPurposeMsg
| FinancialDetailsMsg FinancialDetailsMsg
The new message types can live in the same file as the top-level Msg type.
They can also be extracted to different files. That’s your choice.
The next thing to tackle is our update function, since it needs to mirror our
Msg type.
Nested Update Functions
I’ve seen people advocate for page-specific update functions which take a
page-specific model and return a tuple of that page-specific model and a
page-specific Cmd Msg equivalent. This is typically where you see Cmd.map
sneaking in. These functions almost inevitably end up needing something from
the top-level application-wide state, so you’ll often see some type signature
like this:
updatePersonalInformation
: PersonalInformationMsg
-> Model
-> (PersonalInformationModel, Cmd PersonalInformationMsg)
-> (Model, Cmd Msg)
This is way too complex already, and this approach doesn’t even actually buy you anything.
The far simpler way to do this is to have every nested update function take a
page-specific message, the entire application state, and return the same type
for that state along with the top-level Msg type, like this:
updatePersonalInformation : PersonalInformationMsg -> Model -> (Model, Cmd Msg)
updatePersonalInformation msg model = case msg of
SetFirstName a -> -- …
SetLastName a -> -- …
SetAddressLine1 a -> -- …
-- etc…
update : Msg -> Model -> (Model, Cmd Msg)
update msg model = case msg of
NoOp -> (model, Cmd.none)
SetPage page -> ({ model | page = page }, Cmd.none)
PersonalInformationMsg subMsg -> updatePersonalInformation subMsg model
LoanPurposeMsg subMsg -> updateLoanPurpose subMsg model
FinancialDetailsMsg subMsg -> updateFinancialDetails subMsg model
No complicated type signatures. No juggling of message types. No Cmd.map. Easy.
Of course the whole point of our update function is to advance the state of
our model, and the structure of that model is also something that can swell and
become unwieldy, so that’s what we will dissect next.
Record Surgery
Near the inception of the project, all of our individual bits of state might
exist at the top level of our Model, which is typically represented as a
record. Perhaps something like this:
type alias Model =
{ page : Page
, firstName : String
, lastName : String
, addressLine1 : String
-- …more personal information fields
, purchaseItemCategory : ItemCategory
, purchaseItemEstimatedValue : Money
-- …more loan purpose fields…
-- …and also financial details, and system-wide state, etc…
}
Like the parts of our project we’ve addressed previously, this also can turn into a bit of a mess as it grows. Both application-wide data and page-specific data are mixed in together which feels a bit haphazard. Fortunately, grouping and extracting these fields is typically rather intuitive. We can start by grouping page-specific parts of the state together, and then group further until it no longer feels messy.
type alias Address =
{ line1 : String
, line2 : String
, city : String
, postcode : String
-- …
}
type alias PersonalInformation =
{ firstName : String
, lastName : String
, address : Address
-- …
}
type alias LoanPurpose =
{ purchaseItemCategory : ItemCategory
, purchaseItemEstimatedValue : Money
-- …
}
type alias FinancialDetails = -- …
type alias Model =
{ page : Page
, personalInformation : PersonalInformation
, loanPurpose : LoanPurpose
, financialDetails : FinancialDetails
}
The problem now however is that when we wish to update a deeply-nested field, we need to write all of the code to unwrap each level until we arrive at the depth we need. Illustrated another way, let’s say we want to update the first line of the applicant’s address.
Retrieving the value of this field is no problem, as we can use Elm’s dot syntax to succinctly get us all the way there, like this:
model.personalInformation.address.line1
What we can’t do here however is update that field in a similar fashion, i.e., Elm won’t allow us to write something like this:
-- This won't work
{ model.personalInformation.address | line1 = newLine1 }
-- This also won't work
{ model | personalInformation.address.line1 = newLine1 }
The naïve way to unwrap and subsequently update the field in this record is to write something like this:
updatePersonalInformation : PersonalInformationMsg -> Model -> (Model, Cmd Msg)
updatePersonalInformation msg model = case msg of
SetFirstName _ -> -- …
SetLastName _ -> -- …
SetAddressLine1 newLine1 ->
let
personalInformation =
model.personalInformation
address =
personalInformation.address
newAddress =
{ address | line1 = newLine1 }
newPersonalInformation =
{ personalInformation | address = newAddress }
in
({ model | personalInformation = newPersonalInformation }, Cmd.none)
SetAddressLine2 _ -> -- …
That’s 14 lines of code to update one single field. Not only is this single example somewhat confusing to follow, you also need to imagine how this update function will look when taking into account the five or so other fields just in the address record! This is — quite frankly — pretty terrible. The trick here is not to stare out of the window and contemplate rewriting everything in ClojureScript. Instead, the thing to do is write a whole bunch of lenses.
Conceptually, the lens functions we need are rather simple. We need one function to bridge the gap between each level of our information architecture, and then we just need to glue those functions together.
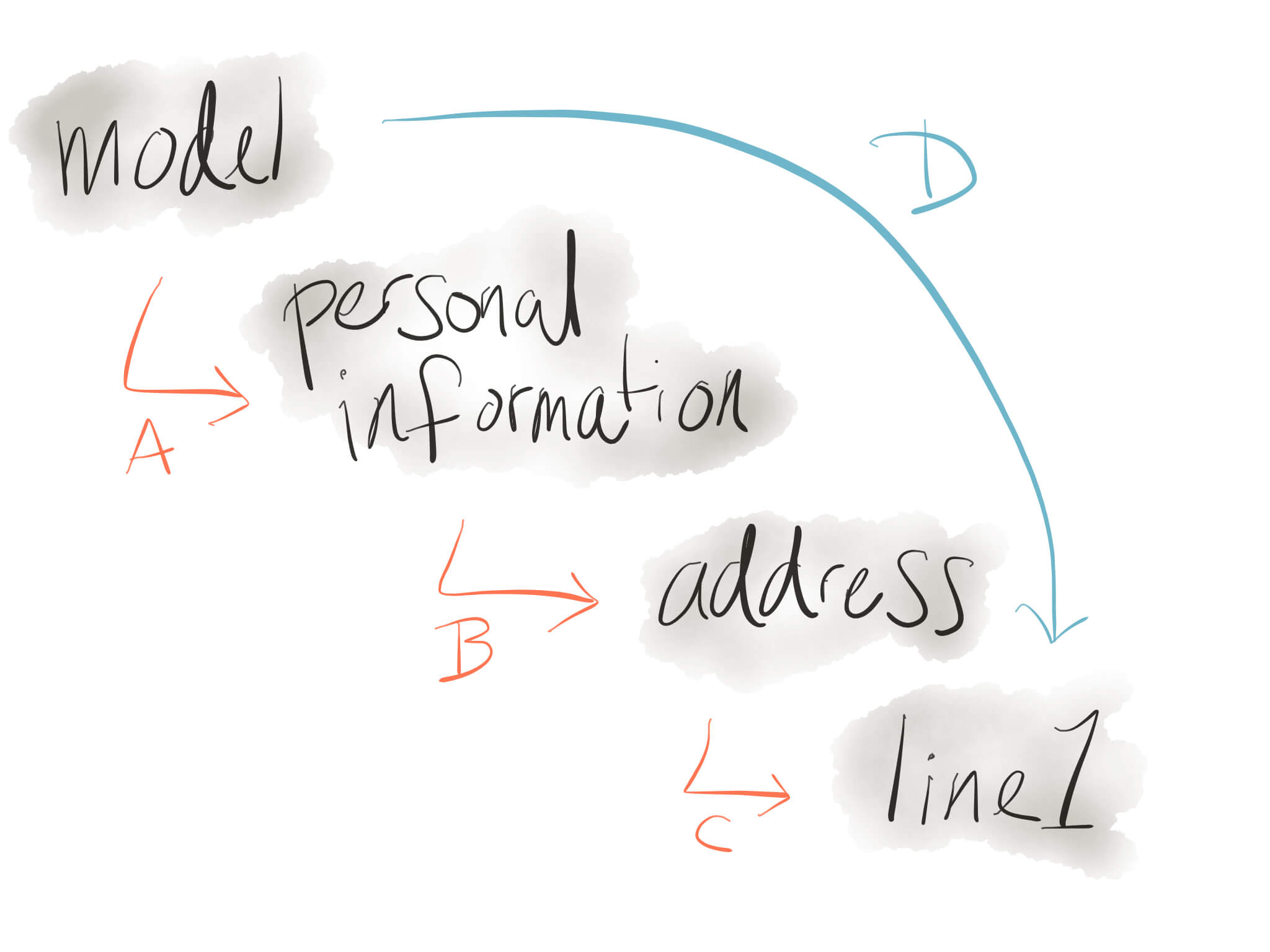
In the diagram above, the orange arrows represent the individual lenses that we
want in order to move between the different levels of our data structure. The
blue arrow is the lens that we will want to use in our
updatePersonalInformation function, and we get this bigger lens by composing
the three smaller lenses together.
We can write these functions with a handy library called elm-monocle
(and of course other libraries are available), and they would look something
like the following:
import Monocle.Compose
import Monocle.Lens exposing (Lens)
-- lens A
personalDetailsL : Lens Model PersonalDetails
personalDetailsL = Lens .personalDetails (\b a -> { a | personalDetails = b })
-- lens B
personalDetailsAddressL : Lens PersonalDetails Address
personalDetailsAddressL = Lens .address (\b a -> { a | address = b })
-- lens C
addressLine1L : Lens Address String
addressLine1L = Lens .line1 (\b a -> { a | line1 = b })
-- lens D
personalDetailsAddressLine1L : Lens Model String
personalDetailsAddressLine1L : personalDetailsL
|> Monocle.Compose.lensWithLens personalDetailsAddressL
|> Monocle.Compose.lensWithLens addressLine1L
You can pretty much ignore the implementation of each of these lenses, as they
are mostly just mechanical transformations between each level of our model.
It’s better instead to read the type signatures which clearly show that the
first lens gets you from Model to PersonalDetails, the second lens takes
you from PersonalDetails to Address, the third lens takes us one level
deeper, and the fourth lens combines the first three, taking us all the way
from our top-level Model right the way down to the String that represents
the first line of the applicant’s address.
Writing out all of these lenses is admittedly somewhat tedious and it’s mostly boilerplate — which makes me wonder if these couldn’t be generated in some way; a research topic for another day. It’s at least easy enough to just stick all this boilerplate in its own file somewhere and not clutter up the parts of the code where more interesting things happen. Once we have these lenses though, we’re able to drastically clean up our update functions.
Instead of the mess we had earlier, we could have something like this:
updatePersonalInformation : PersonalInformationMsg -> Model -> (Model, Cmd Msg)
updatePersonalInformation msg model = case msg of
SetFirstName _ -> -- …
SetLastName _ -> -- …
SetAddressLine1 newLine1 ->
(personalDetailsAddressLine1L.set newLine1 model, Cmd.none)
SetAddressLine1 _ -> -- …
This is much more elegant, and the nature of this API means it works even more beautifully when updating several fields at once. You could write something like the following contrivance, for example:
flip : (a -> b -> c) -> b -> a -> c
flip f b a = f a b
updateExampleFields : ExampleMsg -> Model -> (Model, Cmd Msg)
updateExampleFields msg model = case msg of
SetManyModelFields foo bar baz spam eggs -> model
|> nestedExampleFooL.set foo
|> nestedExampleBarL.set bar
|> nestedExampleBazL.set baz
|> montyPythonBreakfastSpamL.set spam
|> montyPythonBreakfastEggsL.set eggs
|> flip Tuple.pair Cmd.none
Writing composable setter functions is possible without a lens library, but the code you end up writing will look so similar to idiomatic usage of elm-monocle anyway so I see no reason not to use the library and standardise on a consistent API across your project.
I have seen several people recommend avoiding having to write lenses by just not having the problem of deeply-nested record types in the first place, and instead to have as shallow a model as possible. I don’t agree with this kind of hand-waving as it fails to take into account the possibility for types to be generated on the backend so the shape of the model never goes out of sync across that boundary. For a non-trivial application, I believe it’s cheaper to use code generation to derive the type definitions, JSON encoders, and JSON decoders than it is to manually write all of it and try to make sure everyone on your team is disciplined enough to always make those changes.
As a brief aside, I will at this point sympathise with people who have criticised Elm in the past for some of its most vocal proponents being frustratingly unhelpful.
Relatedly, I’ve also come to view lenses as a such a huge mistake that if there were a way for the language to make it impossible to implement lens libraries, I would advocate for it. (Unfortunately, they are not possible to rule out.)
I’m sorry, but sanctimoniously dismissing a powerful technique for working with data structures in a schema that they’ve come to exist in organically without even bothering to justify the dismissal or provide an alternative technique is just bad.
Sometimes, like… People are just, kinda, wrong? You know?
Moving swiftly on, and now that our model is satisfactorily wrangled, we can attack the last part of this puzzle which is rendering our model on the page.
The Closed Loop
In the same way that your nested model update functions should return a
top-level Msg type rather than some page-specific message type, the view
functions should also return the top-level Msg type.
-- Bad
personalDetailsView_ : Model -> Html PersonalDetailsMsg
-- Good
personalDetailsView : Model -> Html Msg
The question here then is: how do we send a page-specific message into the
runtime if the view function has declared in its type signature that it returns
a top-level Msg type in a Html context? This turns out to be quite simple.
We can just use function composition to join the different constructors
together.
If we consider a view function that renders an input for modifying the first line of the applicant’s address as before, we might write it like this:
addressLine1Input : Model -> Html Msg
addressLine1Input model =
input
[ type_ "text"
, value model.personalDetails.address.line1
, onInput (PersonalInformationMsg << SetAddressLine1)
] []
That’s all there is to it really. I am happily employing all of the techniques described above in a number of Elm projects, each of which span several thousand lines of code.